


文 / 林华 法学博士
编者按:首先说明一下本文标题。AIGC抢跑第一案是指2024年2月8日一审判决上海新创华文化发展有限公司(下称“新华创”)诉某AI公司侵犯奥特曼形象版权的(2024)粤0192民初113号案,OpenAI vs Journalism源自Open AI官网回应纽约时报版权发起的版权诉讼的公开声明标题


第一案为什么是抢跑
(一)AIGC平台第一案简介
广州互联网法院判决的(2024)粤0192民初113号版权侵权纠纷在很多评论中被称为全球AIGC平台侵权第一案,这起案件原告是自2019年起从圆谷制作株式会社获得奥特曼系列形象版权独占授权的新华创,被告是一家未公开披露名称的AI公司。
本案被告通过Tab(化名)工具有偿提供AI图片生成服务,原告新华创以奥特曼及相关关键词作为指示词输入,通过被告Tab生成和奥特曼实质相似的图片。原告经变更诉请,最终将本案案由定为侵害复制权、改编权及信息网络传播权。法院在2024年1月5日立案后于同年2月8日即行做出一审判决。一审判决因双方在上诉期内均未上诉而直接生效。
以ChatGPT等代表的生成式AI给版权法带来了巨大冲击,挑战尤其集中在生成内容是否可以受版权保护,使用版权内容进行AI训练是否合法以及AIGC(AI生成内容)侵权认定。本案直接涉及到前述法律挑战中关联的两项,即以AI生成内容侵权问题的形式倒推AI预训练的合法性。
无论是莎拉·安德森 (Sarah Andersen)等艺术家于2023年1月13日在北加州旧金山地区法院集体起诉Stability AI等的生成式AI真正的图形版权纠纷第一案,还是图片巨头Getty Images在2023年2月3日在特拉华法院起诉Stability AI的版权侵权案(注2),至今都在诉讼程序中反复拉锯,未有宣判的迹象。北京互联网法院即便组织全院优秀法官合议审理近一年的(2023)京0491民初11279号案(注3),判决在版权理论圈还是遇到相当争议。
相较以上同为AIGC版权争议案件的审理,广州互联网法院本院对本案的判决可以说一切从快从简,不但适用独任审判的简单程序,而且连同开庭到发出判决只用了30多天,超高效率之外难免有抢跑之嫌。而对被告及涉案AI工具都加以化名,也让研究者难以重现涉案技术环境和系争行为。
如朱文郁、孙磊等律师感叹“全球首起AIGC平台侵权案”以迅雷不及掩耳之势判决,并针对这个技术最前沿案件可能存在问题给出的不同意见(注4),本案被告在技术上并不是AI模型提供者,而只是调用第三方大模型接口再向最终用户提供二手绘画服务。这在判决提及”案涉网站的AI绘画功能是通过第三方服务商实现”,以及法院对“关于原告将案涉奥特曼物料从其训练数据集中删除的诉请,因被告并未实际进行模型训练行为,本院对该项诉请不予支持”的认定可以看得很清楚(注5)。
被告身份只是AI服务的渠道方,法院就没有具体分析AI大模型预训练的合法性的理由,这一点影响了本案的典型意义。
本文以下先从第一案判决中的法律依据进行展开。
(二) 在版权法和监管规则间摇摆
1.判决重点引用《生成式人工智能服务管理暂行办法》
几乎所有版权研究者都关注到第一案判决大篇幅引用国家网信办等七部门在2023年联合发布的《生成式人工智能服务管理暂行办法》(下称《暂行办法》)。
判决首先引用《暂行办法》第四条“生成式人工智能服务提供者应当遵守法律、行政法规,尊重社会公德和伦理道德,应当尊重知识产权”的规定,强调在提供生成式人工智能服务时应尽合理的注意义务,并以此依据论证被告身为AI服务提供者未尽合理注意义务的分析:
1)欠缺《暂行办法》第十五条规定AI提供者应当建立健全的投诉举报机制;
2)欠缺《暂行办法》第四条规定AI提供者向用户进行的潜在风险提示;
3)欠缺《暂行办法》第十二条规定AI提供者对生成内容进行标识
2.判决引用但并没有以《暂行办法》作为裁判依据
AIGC第一案判决的特别之处不止在版权侵权案件裁判中大幅引用《暂行办法》,还在虽然引用却没有将《暂行办法》作为裁判依据。
参见判决书主文,明确提到的裁判法律依据是《著作权法》第二条第二款、第十条、第十二条、第五十二条、第五十三条、第五十四条,《最高人民法院关于审理著作权民事纠纷案件适用法律若千问题的解释》第七条第一款、第二十六条,以及民事诉讼程序规则,并不包含《暂行办法》。
判决在版权法和暂行办法间穿梭,铺垫了一个复杂的论证和依据体系。客观而言判决的操作很有特点,既有不错的文书技巧但也为类案适用带来不低的风险。
3.技巧和风险并存
AIGC第一案判决并没有直接依据《暂行办法》认定被告侵权,而是在“关于应否赔偿损失的问题“环节,用来论证“被告未尽到注意义务,主观上存在过错”。
首先,判决只援引《暂行办法》证明被告没有尽注意义务,这步操作既调用《暂行办法》的规定又没有将其作为法律依据,裁判技巧上倒是弓马娴熟,立于不败之地;
其次,判决没有充分说明被告身份和对应法律规则,在这种情况下援引《暂行办法》使涉案行为的法律性质变得含糊,为类案适用带来困扰。所以迄今我们看到的评论都认为本案是AIGC平台侵权案,准确说应当是AIGC服务渠道的侵权纠纷。
(三) 裁判引用《暂行办法》应当考虑的风险
接上,我们分析在人工智能著作权纠纷裁判中引用《暂行办法》可能产生的问题和风险。
1)回转式指引
《暂行办法》在体例上不属于版权立法,既不能和版权法现有规则相冲突也没有实质性填补版权法的空白。《暂行办法》涉及版权的规范或者垂直于行政监管,典型如前引第十二和十五条;与版权实体权利相关的规定都是指引式立法,即重复引导回版权法作为依据,典型如第四条中“提供和使用生成式人工智能服务,应当……(三)尊重知识产权”。
《暂行办法》涉及版权实体权利的规定都采取指引式立法,说明《暂行办法》无法替代版权法,补充价值也集中在监管一块。
2)立法自有不足
《暂行办法》属于具有试验性质的AI立法,全球范围的AI立法经验都并不充分。在很多情况下生成式AI生成具体内容的过程并不是由大模型独立完成,而是由大模型、训练数据集、用户等多方主体参与和共同决定。
举例说明,Stable Diffusion等典型的图片生成式模型不仅允许用户使用官方以外的图像训练数据集,而且支持用户直接使用图片生成图片(即图生图)。在这种情况下用户可以自行选择生成内容参照系并对生成结果产生决定性影响。
《暂行办法》第七条规定:“生成式人工智能服务提供者应当依法开展预训练、优化训练等训练数据处理活动,遵守以下规定:(一)使用具有合法来源的数据和基础模型;(二)涉及知识产权的,不得侵害他人依法享有的知识产权......”。该项规则只将AI服务提供者列为数据训练责任人,并没有考虑到多个主体参与训练和生成过程的情形。
具体举例,以下是一幅艺术家抱怨自己作品被AI抄袭,事实上这是典型的利用AI对他人作品1对1“炼丹”的结果。这类行为本质是用AI对他人作品进行修改,应当由修改人承担法律责任,AI作为纯粹工具与生成结果不产生法律上的关系。

3)回避分析侵权行为的法律性质
本案判决中引用《暂行办法》以证明被告有且未履行合理注意义务。这里涉及的一个重要理论问题,即版权法下的直接侵权责任适用无过错原则,只有间接侵权才适用过错原则。这也是只有技术服务提供者等第三方平台/工具才可以主张适用通知删除规则,内容提供者无法援引避风港的根本原因。
如果认为被告违反注意义务才构成侵权责任,等于将被告认定为技术服务提供方从而适用间接侵权认定。尤其判决提及被告应当提供投诉举报机制,这正是为第三方平台量身定制的通知删除规则。然而判决并没有对涉案人工智能服务是否属于技术服务或者内容服务做出结论,且裁判主文又是援引《著作权法》中对直接侵权责任的规定确认被告侵权,矛盾更加显而易见。
需要说明的是在判决引用《暂行办法》分析被告过错的论述部分,提到”赔偿损失责任的承担需要考虑被告的过错问题“,这个观点在主流理论观点中找不到依据,在《著作权法》中也没有支持。以判决所依照的《著作权法》第五十二、第五十三、第五十四条规定,行文都是”未经著作权人许可”而有行使专有权行为的即承担包括赔偿损失等民事责任,均是直接推定过错而无提及注意义务。

AIGC内容争议本质是通过输出实现对输入端的控制
(一)为什么通过控制生成内容实现控制训练素材
1.大模型生成内容过程的两端
生成式人工智能纠纷的确是版权法最前沿的课题。了解大模型生成内容版权纠纷的本质才能准确适用法律,这一点比了解大模型实现生成的技术原理和过程更加重要。但法律分析是建立在最基本的客观技术基础之上,所以在解析AI生成内容法律纠纷实质之前有必要简要解释AI生成内容的过程。
最简单的说,无论生成文字、图片或者视频内容的AIGC大模型,无一例外需要通过巨量数据作为语料素材的预训练。大模型通过天量语料的预训练独立学习任何类型文本中的规律,形成根据外部指令生成新内容的能力。其中预训练是输入阶段,生成内容就是输出阶段。了解生成式技术的细节实际对分析本案帮助不大,法律同行如有兴趣欢迎浏览本公号上一篇《妥协是渐进的艺术......》以及《人工智能数据训练的法律竞争》。
2.起诉生成内容侵权是为曲线控制预训练内容
我认为从广州互联网法院审理的生成式AI第一案到Open AI和纽约时报火热进展中的诉讼,包括Getty诉Stability AI等有关人工智能生成内容侵权的版权纠纷案件,本质都是语料素材版权人通过起诉大模型生成内容侵权来实现对大模型使用版权内容进行训练的控制,即希望通过起诉AI输出侵权来限制预训练阶段的内容输入。有两个主要理由支持这项观点:
1)直接控制AI输出难度高且效率低
和专利权不同,版权并不具有绝对垄断效力,因为版权保护独创但不禁止其他人独立创作出(基于巧合)即使完全一样的作品。对AI生成结果的诉讼效力只及于个案,且获得胜诉结果需要排除AI独创,所以难度高且效率低。
与此同时,基于生成式技术的原理可知AI缺乏相关语料的预训练就无法生成指定结果,控制预训练显然是控制所有相关内容生成最高效的办法。因此起诉AI输出内容侵权只是维权手段,控制AI使用版权内容进行训练才是维权目的。
AIGC平台第一案判决中提及原告诉请将案涉奥特曼物料从AI训练数据集中删除,说明原告意识到控制输入端的重要性。但因该案被告仅为AI服务渠道商无法控制模型训练,法院未支持该诉请。
2)规避被告主张预训练的合理使用
如果原告为追求高效直接起诉AI预训练侵权,会遇到比起诉生成内容侵权难度更大。除了原告难以掌握AI训练集的具体证据,一个重要的法律障碍是被告可以主张合理使用的抗辩。
AI预训练过程会对语料素材进行临时复制。从目前中国立法中无法得出生成式大模型使用受版权保护的素材和语料进行预训练是否适用合理使用的必然结论。考虑到日本欧洲美国都在积极推动(注6),以及全球在人工智能赛道的白热化竞争,中国法院接受AI技术服务提供者对预训练素材合理使用抗辩的概率是偏大的。
支持预训练适用合理使用绝不只是利益平衡,还有法理的有力支持。我在先前文章中援引过萨格教授在美国参议院听证会作证时提出的观点:利用受版权保护作品训练生成人工智能是非表达性使用,通常属于合理使用(”Training generative AI on copyrighted works is usually fair use because it falls into the category of non-expressive”)(注7)。
(二)生成式预训练也应当受版权约束
1.约束预训练的必要性
生成式人工智能的基本技术逻辑决定了AI并不以复制或者抄袭为目的,甚至在通过预训练学习到数据特征后即无需保存语料。正如萨格教授所说,生成式人工智能”并不是为了复制原创而设计“(注8)。
尽管AI预训练应当可以主张合理使用,预训练同样当然受版权约束。生成式AI可能发生幻觉,同理也可能因为程序出错而不应有的直接复现训练素材。在AI出错情况下预训练阶段的合理使用抗辩即在该个案中失效。
从权利平衡角度看,尽管AI预训练在逻辑上符合合理使用要件,人工智能发展也会对技术和人类社会的进步有不可估量的正向作用,但生成式技术的突然勃兴对版权权利人和内容/创意产业传统发展环境的冲击不容忽视,这是在认可对预训练主张合理使用同时应当有效控制合理使用范围的现实考量。所以萨格教授才会在对预训练适用合理使用的主张下增加”如果LLM(语言大模型)经过适当训练并有适当保护措施“的条件(注9)。
2.主流AI主动约束预训练
通过限制生成内容等方式约束预训练,不但是法理的需求也是OpenAI等代表的主流生成式人工智能已落地的措施。
OpenAI官方发布的服务条款(注10)第三条(b)中明确承诺OpenAI对ChatGPT Enterprise客户的赔偿义务包括针对客户使用或分发输出侵犯第三方知识产权的索赔。前述承诺在损害是由用户故意引发等情行下才无效。
直接看实例:
TEST 1【画一个迪迦奥特曼】

在这个测试中ChatGPT和第一案被告一样没有拒绝生成和迪迦奥特曼形象相似的图像(头盔有点明显区别)。当我们以为浓眉大眼的GPT也叛变的时候,后面的测试就变得有趣起来了。
TEST 2【画一个七龙珠 孙悟空】

当我要求画七龙珠里的孙悟空(Goku),GPT突然内向,只同意出一幅受Goku启发创作的图像。
TEST 3【画米老鼠】

在要求画米老鼠的时候,GPT变成了正经AI,一口拒绝了要求。似乎OpenAI合规偏重于美国内容。
TEST 4【画Taylor Swift】
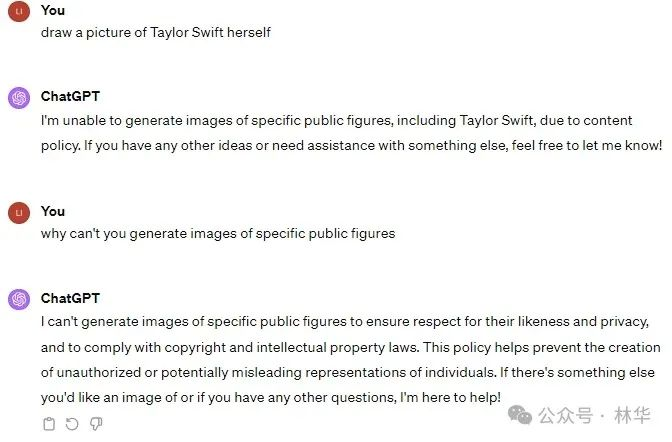
在要求画当红歌手霉霉(Taylor Swift)时,GPT以不符合内容政策理由(due to content policy)一本正经的拒绝,并表态维护隐私和尊重版权(I can't generate images of specific public figures to ensure respect for their likeness and privacy, and to comply with copyright and intellectual property laws)。
通过以上测试例,GPT有完整的内容合规制度并实际执行,但因不确定的原因在处理迪迦奥特曼时脱轨了。如果新华创在美国起诉OpenAI,倒可以看看法院是否会接受限制直接生成以奥特曼形象作训练素材的诉请。

纽约时报诉OpenAI案的看点
(一)纽约时报不讲武德?
武力和武德是两回事。纽约时报起诉OpenAI是否有事实和法律依据是一个判断,原告维权的手段是否合理则是另一个判断。
纽约时报主张GPT-4的输出结果与自己作品大量重复,因OpenAI授权微软作为合作方在其必应搜索的”Copilot”智能服务中支持GPT-4商业化,遂将OpenAI和微软两大企业一并诉上纽约南区法院,主张被告擅自使用大量纽约时报版权文章进行大模型预训练,与原告进行直接竞争,要求被告承担停止侵权、恢复原状和赔偿损失责任。(注11)
对于纽约时报的两项主张我无法理解。
首先,原告在诉状中表示被告非法复制和使用《纽约时报》独一无二的宝贵作品,造成“数十亿美元的法定和实际损害”。检索了一下,发现纽约时报2023年全年经营收入为24.26亿美元。不知道原告怎样证明2023年4月才发布的GPT-4能给原告造成超过全年营收的损害。
原告诉讼请求中只有笼统的要求赔偿但没有提出具体金额。如果原告在诉讼过程中固定索赔数十亿美元,想看看诉讼费算下来有多少。另外纽约时报请的律师应该不是马斯克请过开价60亿美元的哪些律师吧。
其次,原告要求法院销毁所有GPT或其他LLM模型以及所有包含纽约时报作品的培训集,这项主张也到了荒诞的程度。合法主张的侵权救济以恢复原状和制止侵权必要为限,即使算入惩罚性赔偿也无论如何不可能及于销毁GPT技术的地步。
法律的确没有限制原告提出出格的诉讼请求,毕竟所有诉请都由法院最终裁定。原告荒唐的主张虽然仍属于合法行使诉讼权利,但也应该准备好被批评。纽约时报在诉讼中可能在证据和法律依据上占有优势,诉求在策略上或许也可以理解,但吃相属实有点难看。
(二)两大看点
本文从中国的AI平台侵权第一案展开,就不再详述纽约时报诉OpenAI案的具体细节,直接跳到本案和”AIGC平台第一案”不同的两大看点。
1.案件影响不可同日而语
如前分析,广互审理的”AIGC平台第一案”本质是权利人和AI服务渠道的侵权纠纷,虽然判决的观点和分析路径会对未来AI生成内容(AIGC)版权纠纷产生一定影响,但难以在OpenAI等真正AIGC平台的版权纠纷中直接适用。
同时,OpenAI和纽约时报的诉讼是OpenAI陷入的一堆AIGC版权争议中最受关注的一个。在纽约时报起诉前已经有包括《权力的游戏》作者老Martin在内的多位作家集体起诉OpenAI未经许可使用版权保护内容进行训练(我觉得这批案件不如Times案件典型,因为作家集体诉讼的依据只是GPT生成的小说摘要,很明显会遇到版权合理使用的狙击),而在纽约时报起诉后一批媒体媒体也跟进加入到对OpenAI的起诉中。
OpenAI和纽约时报的诉讼会深度触及AI数据训练以及生成内容与训练素材关系的合法性判断,不但会影响AIGC文字内容的版权纠纷,也会对Mid journey和Stable Diffusion一众图形生成AI的版权诉讼产生明显影响。
2.诉由宽度大,覆盖完整
基于美国民事诉讼对诉讼事由的包容度,纽约时报在对OpenAI的诉状中一揽子提出包括版权、商标、不正当竞争等多项侵权事由。更值得关注的是,原告在版权诉讼一个方向中也同时提出多项侵权事由,这恰好覆盖了AIGC内容版权侵权争议的各种可能。
纽约时报向OpenAI主张的版权侵权主要包括诉状第124段主张故意使用原告版权内容进行数据训练的故意侵权,第二部分提到OpenAI和微软合谋的替代侵权(Vicarious Copyright Infringement),以及第四部分提到帮助最终用户获取侵权内容的共同侵权。

用同人标准测试纽约时报诉OpenAI
(一)用人类标准判断AI侵权
如果同意将AIGC版权侵权争议拆解为输入阶段预训练的侵权争议,以及输出阶段的内容生成的侵权争议,则不论广互审理的奥特曼AIGC案还是纽约时报诉OpenAI案,合理使用只适用于对预训练阶段的抗辩。对AIGC生成内容阶段的侵权争议应当采用何种判断方法是值得讨论的问题。
我个人认为对AIGC输出阶段的侵权争议,可以搁置AI生成技术和人类创作过程的差异,采用同样的侵权认定标准进行判断。这种判断方法的实质是在法律适用的角度抹平AI和人类在内容生成过程与方法上的区别,用人类行为的判断标准统一AIGC侵权判定。
(二)用人类标准统一AIGC裁判的理由
面对复杂问题的简单处理会产生效率上的优势,这一项可能是采用同人标准在表面上最直观的优点。但简化复杂问题所带来缩短判断路径的优点远不足以支持确认同人标准,因为公正是法律更高的追求。
用和人类相同的标准判断AI侵权还是一种测试,尚不是一项普遍认可的法律原则或者标准。但之所以应当用同人标准判断AIGC侵权,最根本的原因不在于裁判的高效以及避免形成新理论的漫长过程,就是因为同人标准本身就适合迄今出现的所有AI,具有充分的公正性与合理性。
同人测试不仅在AIGC侵权判断上可行,在对AI数据训练过程合法性的判断中同样成立。主张对数据训练适用合理使用的观点,就是首先适用人类行为的合理使用标准再结合AI训练过程中临时复制和训练完成后无需保留原件特点所做的判断。对AI数据训练阶段广泛使用的爬虫技术,适用和人类行为一样的判断标准也完全可以得出合法且合理的结论。
把视野再次放大,不仅对AIGC相关版权侵权纠纷应当采用同人标准进行判断,在人工智能相关不正当竞争和商标侵权判断中都可以适用。相反,如果要在同人标准之外另辟专用于AI侵权的判断标准,在必要性、合理性以及可行性上显然都不充分。
(三)为什么纽约时报能赢
如果同意对AIGC生成内容的侵权判断采用同人标准,OpenAI会不会输掉和纽约时报的诉讼就不难判断。直接上两张纽约时报诉状中的内容对比图:

【诉状第30页】

【诉状第31页】
补充说明,纽约时报诉状中这两段证据举例不是单纯的事实信息,构成受版权保护的有独创性的分析报道。由于OpenAI生成内容和原文几乎全文一致,在非提供摘要情况下也不构成合理使用。
至于OpenAI主张纽约时报陷阱取证,我个人认为客观上不算,唯一问题是确定被告单独侵权还是和用户一起构成共同侵权。在纽约时报诉请覆盖前述两种侵权的情况下,OpenAI应该做好败诉准备。
注释:
1.
2. 案号:3:23-cv-00201
3. 案号:1:23-cv-00135-UNA
4. 朱文郁 范臻 孙磊:《AIGC平台“注意义务”的“全球首高”》,https://mp.weixin.qq.com/s/FMV_lY-Fptr2Nvz132PVPQ
5. (2024)粤0192民初113号案
6. “日本、以色列、英国属于全面开放AI数据训练版权禁区的第一梯队;美国、韩国属于可能通过扩大解释现有合理使用制度全面覆盖AI数据训练的第二梯队;欧盟属于对AI数据训练有条件适用合理使用的第三梯队”,见林华:《人工智能数据训练的法律竞争》,https://mp.weixin.qq.com/s/N8qbAPDM7bUcuMUfBDV8Vw
7. 转引林华:《人工智能数据训练的法律竞争》,https://mp.weixin.qq.com/s/N8qbAPDM7bUcuMUfBDV8Vw.
8. 同上
9. 同上






TEL:(+86) 10-5166-9666
FAX:(+86) 10-6527-9996
E - MAIL:bd@tiantonglaw.com
ADDRESS:Yard 3, Nan Wan Zi, Nan He Yan Street,
Dongcheng District, Beijing, China
JOIN US:HR@tiantonglaw.com



Copyright TianTong Law Firm 沪ICP备2024088680号-1  (Beijing) ICP No 11010102004236号
(Beijing) ICP No 11010102004236号